Note: This was originally published on the MongoDB Engineering Blog on April 30, 2019 here by Henrik Ingo and myself. Please read it there assuming the link works. I have copied it here to ensure the content does not disappear. The links in the article are the original links.
In an effort to improve repeatability, the MongoDB Performance team set out to reduce noise on several performance test suites run on EC2 instances. At the beginning of the project, it was unclear whether our goal of running repeatable performance tests in a public cloud was achievable. Instead of debating the issue based on assumptions and beliefs, we decided to measure noise itself and see if we could make configuration changes to minimize it.
After thinking about our assumptions and the experiment setup, we began by recording data about our current setup.
Investigate the status quo
Our first experiment created a lot of data that we sifted through with many graphs. We started with graphs of simple statistics from repeated experiments: the minimum, median, and maximum result for each of our existing tests. The graphs allowed us to concisely see the range of variation per test, and which tests were noisy. Here is a representative graph for batched insert tests:
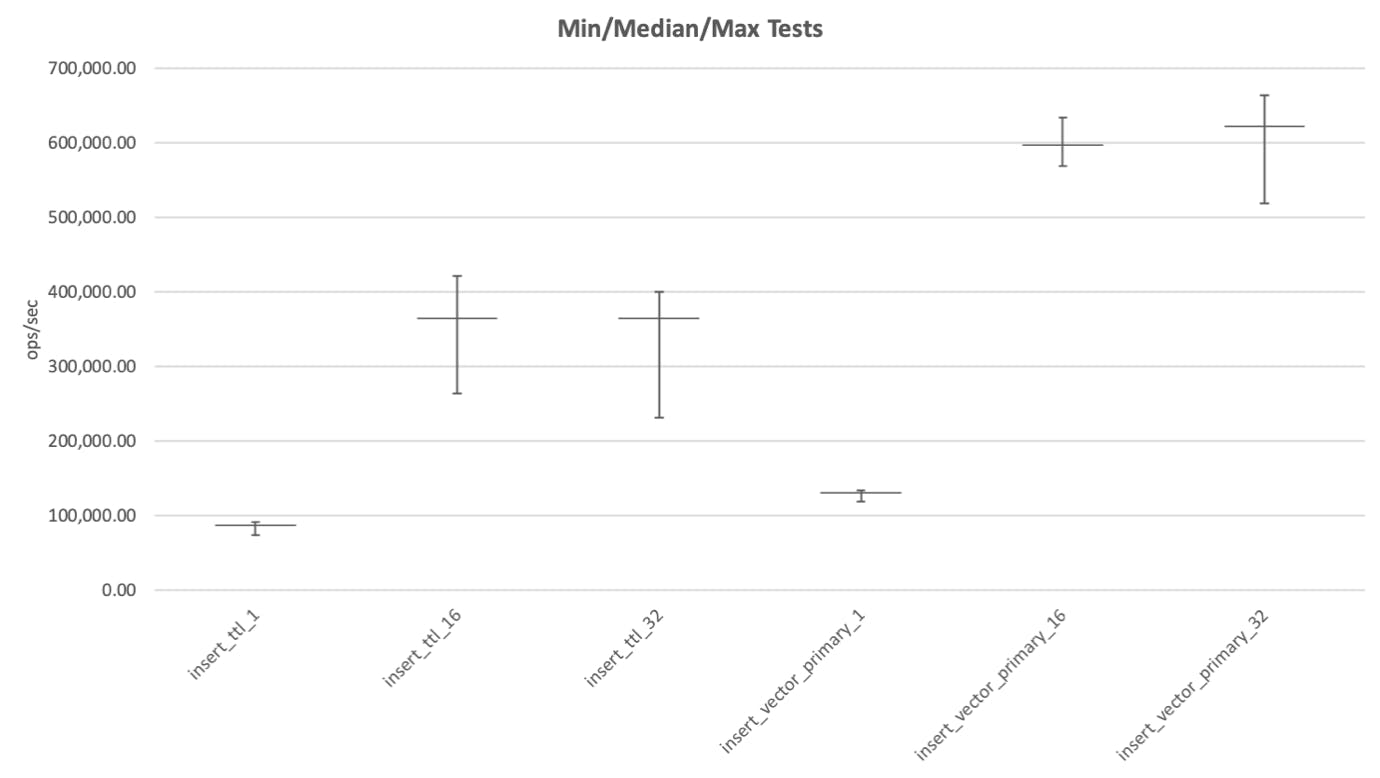
In this graph you have two tests, each run three times at different thread levels (this is the integer at the end of the test name). The whiskers around the median, denote the minimum and maximum results (from the 25 point sample).
Looking at this graph we observe that thread levels for these two tests aren't optimally configured. When running these two tests with 16 and 32 parallel threads, the threads have already saturated MongoDB, and the additional concurrency merely adds noise to the results. We noticed other configuration problems in other tests. We didn't touch the test configurations during this project, but later, after we had found a good EC2 configuration, we did revisit this issue and reviewed all test configurations to further minimize noise. Lesson learned: When you don't follow the disciplined approach of "Measure everything. Assume nothing." from the beginning, probably more than one thing has gone wrong.
EC2 instances are neither good nor bad
We looked at the first results in a number of different ways. One way showed us the results from all 25 trials in one view:
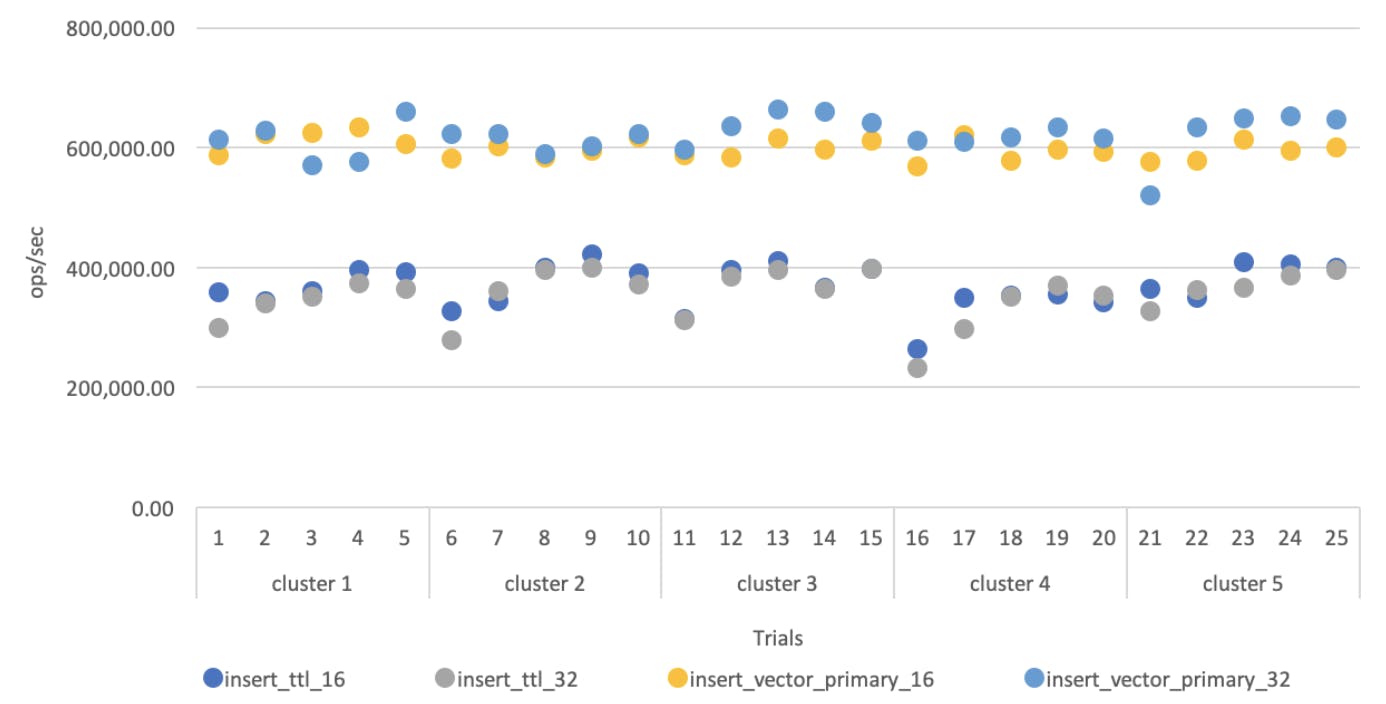
As we examined the results, one very surprising conclusion immediately stood out from the above graph: There are neither good nor bad EC2 instances.
When we originally built the system, someone had read somewhere on the internet that on EC2 you can get good and bad instances, noisy neighbours, and so on. There are even tools and scripts you can use to deploy a couple instances, run some smoke tests, and if performance results are poor, you shut them down and try again. Our system was in fact doing exactly that, and on a bad day would shut down and restart instances for 30 minutes before eventually giving up. (For a cluster with 15 expensive nodes, that can be an expensive 30 minutes!)
Until now, this assumption had never been tested. If the assumption had been true, then on the above graph you would expect to see points 1-5 have roughly the same value, followed by a jump to point 6, after which points 6-10 again would have roughly the same value, and so on. However, this is not what we observe. There's a lot of variation in the test results, but ANOVA tests confirm that this variation does not correlate with the clusters the tests are run on. From this data, it appears that there is no evidence to support that there are good and bad EC2 instances.
Note that it is completely possible that this result is specific to our system. For example, we use (and pay extra for) dedicated instances to reduce sources of noise in our benchmarks. It's quite possible that the issue with noisy neighbours is real, and doesn't happen to us because we don't have neighbours. The point is: measure your own systems; don't blindly believe stuff you read on the internet.
Conclusion
By measuring our system and analyzing the data in different ways we were able to disprove one of the assumptions we had made when building our system, namely that there are good and bad EC2 instances. As it turns out the variance in performance between different test runs does not correlate with the clusters the tests are run on.
This is only one of three bigger experiments we performed in our quest to reduce variability in performance tests on EC2 instances. You can read more about the top level setup and results as well as how we found out that EBS instances are the stable option and CPU options are best disabled.
No comments:
Post a Comment